大学院(AIIT)半期のふりかえり
先日私が通っている東京都都立産業技術大学院大学(AIIT)での2Q目成績が出た。
AIITはクォーター制で1年を四半期に分けているので2Qはちょうど折返しといったところである。 そこで入学してからの振り返りしてみたいと思う。
知名度もそれほど高いとは言えないので、入学を検討している人や、すでに入学が決まっている人の参考になれば幸いである。
入学の経緯はこちらに書いてあるので、気になる方は参考にどうぞ ktrw.hatenablog.com
受講スタイル
1コマ90分制で大体平日は2コマあり、最初のコマが18:30~20:00、次のコマが20:10~21:40。土は朝9:00から夕方までコマがある 。
授業は基本的にリモートとオンサイト(教室の人数制限などでNGの場合もあり)のハイブリッドで実施される。
出席の登録はLMS(学習管理システム: 教材とかを配布するオンラインポータル)で期間中に小テストを受ければOKというパターンが多く社会人向けの配慮がなされているところがありがたい。
テストも基本オンラインで実施されており、業務で日程が合わない人は教員に相談できるので社会人向けのバックアップは本当に充実している。
私は一部のサーバー室演習を除き、すべてオンラインで受講した。
振り返り
1Qと2Qでそれぞれ5講義を受講した(すべて情報アーキテクチャコース)
大体1Qで4講義を取れば、修了条件を満たす感じになるが、4講義でも割とハードな印象。 (講義はだいたい週に2回あるので4講義をとると大体土曜も含めて毎日授業がある感じになる)
私は3月で会社を辞めて業務委託と学生を両立させる形になったので5講義でもこなせたが、フルタイムの会社員で4講義以上取っている人は本当に尊敬しかない。
AIITには入学前に科目履修生として事前に単位をストックしておける制度*1があるので、忙しい方はそちらを利用して入学前から計画的に履修スケジュールを立てるのが良いと思われる(実際に科目履修生は結構多い印象)。
1Qと2Qで受講した中で印象的だったのをピックアップして振り返ってみる。
- (1Q)ソフトウェア工学特論
- (2Q) プロジェクトマネジメント演習
- シュミレーターを使ってプロマネの立場を体験する授業
- 疑似体験で少しでもマネージャーの立場を理解できればと思い受講。グループ演習なのでこれも一つのプロジェクトと捉えて、演習を成功させるかも重要なポイントであった
- こういった、独学1人だと学びにくい分野の講義も受講できるのは良い経験であった。
- (2Q) ネットワークシステム特別講義
2Qまでで基礎的な内容ということもあると思うが、今のところ内容が難しすぎてついていけないということはなかった。
入試自体はITのバックグラウンドがない人でも問題ないと思うが、講義内容は知識が全くのゼロの人には講義スピード的についていくのが厳しいだろうなという印象。少なくとも基本情報くらいの知識があると全然違うと思う*2。
後期に向けて
今はネットで海外のCS講義がタダで見れたり、CourseraをはじめMooCがかなり充実しているので、なんで学費と時間を払って学び直しているのかは、しっかり持っていた方が充実するなあと。当たり前のことだが改めて感じた。
後期は、もっと関連書籍を読んだり、グループディスカッションの発言を増やしていきたいなと思った。あとはプロマネ演習のように普段学習しない分野も気になる講義であれば積極的にとっていきたいと思う。
ほんとはQ毎に振り返りたかったけど、だらだらしてたらもう次Qも始まりそうである。 無事に1年次を終えられたらまた振り返りしたいきたいところ。
入学とか講義について詳しく聞きたい人はTwitterとかでDMもらえれば全然応えるのでお気軽にどうぞ。*3
おわり。
産業技術大学院大学に進学することになった
東京都立産業技術大学院大学(AIIT)の情報アーキテクチャコースに合格して、2022年4月から大学院に進学することになりました。 AIITに関する情報はそれほど多くないので、受験の体験談などをシェアしたいと思います。
AIITとは
都内にある専門職大学院です。通常の大学院と違い、研究ではなく実務重視で、コースワーク(Project Based Learning; PBL)を卒業要件とする大学となっています。
専門職大学院とは | 大学概要 | AIIT東京都立産業技術大学院大学
ちなみに情報アーキテクチャコースの学位は情報システム学修士(専門職)になります。学位に関して詳しいわけではないですが、IS(情報システム)であって、CS(コンピュータサイエンス)ではないと思うので、CSにこだわりがある人は注意が必要です。
AIITを選んだ経緯
最初に、情報系で社会人に門戸を広く開けている大学院大学だと、JAISTとNAISTが候補に上がりました。NAISTはオンラインのオープンキャンパスも参加しました。
ただ、進学したいモチベーションとしては、出身の学部が情報系ではなく、今までなんとなく場当たり的にシステム開発していた部分を改めて見直したいという気持ちが強く、「自分は研究がしたいのか?」と考えると思い切ってYESとは言えないなーという感じでした。
そんな折に、情報系の大学院まとめ記事*1を見て、情報系の専門職大学院があることを知り、 特にAIITは「学び直し」を推していたので、自分のニーズにマッチしていると思い決めた感じです。
あとは公立で後述する給付金を利用すると学費がめちゃくちゃ安くなるという点と、学校が都内にあるというのも決め手でした。
受験体験
受験は通年実施しており、いくつかの期に別れています。倍率は公表されていないですが、通期で定員を定めているそうなので、一般的に考えて最初の方が倍率は低いと思われます。
私は2022年入学の最初の一般入試第二期(8月下旬)を受けました。一般入試は小論文と面接(口頭試問)の2つになっています。コロナ渦ということもあり、小論文は専用ページにてテーマが掲載され数日以内に郵送提出、面接はオンラインという形で行われました。
小論文は大学窓口にメールすれば前年度の過去問が貰えます。サラッと募集要項に採点ポイントが記載されているのでそちらも参考すると良いでしょう。
面接の内容は詳しく書けないので、説明会で直接教授に聞くとよいでしょう。当たり前ですが、研究型の大学院ではなく専門職大学院であることは意識したほうがよいかと思います。
給付金について
先述した通り、進学検討の大きな要因になりました。
AIITでは「教育訓練給付金」を受給できます。コースによって金額に差があります。私が進学する情報アーキテクチャコースでは最大80万程の給付を受けることができます。(加えて都民だと入学金が半額になる。ありがたい)
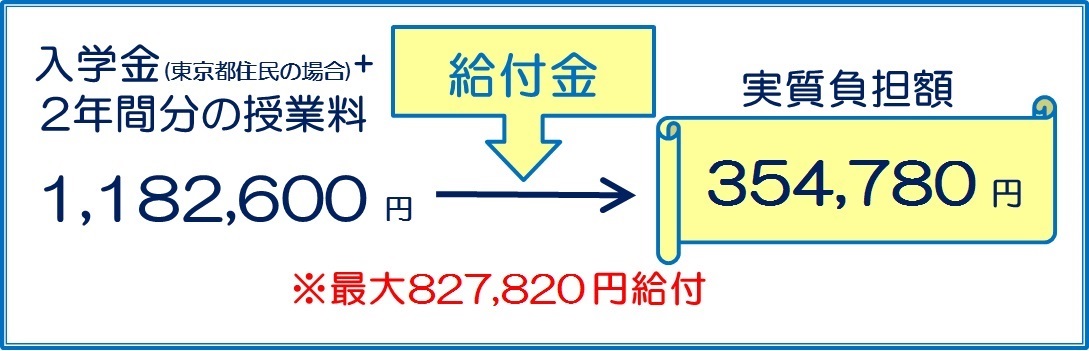 教育訓練給付制度 | 入学案内 | AIIT東京都立産業技術大学院大学 より
教育訓練給付制度 | 入学案内 | AIIT東京都立産業技術大学院大学 より
ちなみに「教育訓練給付金」について調べると、ややこしいことに似たような「教育訓練支援給付金」なる制度があることが分かります。しかしながら、こちらの給付対象者は昼間学校の学生であることが条件みたいで、AIITは夜間学校扱い*2で給付対象外になっているので注意してください。
おわりに
個人的な振り返りも兼ねて、在学中の体験も定期的に記事にしたいと思います。オンライン授業メインっぽいので、縦も横もつながりが乏しくなりそうなのが気がかりです。気軽にTwitter*3とかフォローしてもらえると嬉しいです。おわり。
放送大学の自然言語処理を受けた話
放送大学で開講されている自然言語処理の講義を受講、合格したのでその体験記です
意外とブログ記事がなかったので受講の参考になればと思います
講義を受けた理由
自然言語処理についてのテキストを探していたら
自然言語処理を独習したい人のために - 東京都立大学 自然言語処理研究室(小町研)
で放送大学のテキストが紹介されており、良さそうなのでテキストを購入。
最初はテキストだけ読むつもりでしたがステイホームで時間もあるので、自然言語処理+放送大学の講義がどんなものか知りたく受講をしてみました。
放送大学について
詳しい条件は忘れましたが、単科履修生であれば入学金さえ払えば入学できます。入試とかは特にありませんでした。 入学は4月と10月があったと思います。勝手にCourseraっぽくいつでも聴講できるものと思ってましたが、入学期に入学しないと聴けません。通信指導と言っても大学なのでそれはそうです。
単科の履修生なので、学生証はないかと思ってましたがしっかり発行されました。利用する機会がなかったので分かりませんが、学割も受けられるかもしれません。加えて大学図書館の資料等のリソースもアクセスすることができますし、 アカデミックドメインのgmailも付与されます。
講義について
他の講義は受講していなかったので自然言語処理講義に限った話です。
講義内容は45分ほどで概説される全14回の講義でした文字コードの話から、コーパス、文書分類、系列解析、意味解析、構文解析、応用として情報抽出や機械翻訳などです。 ちなみにニューラルモデルを使った話は機械翻訳のセクションで少しあるくらいです。
講義スタイルは科目によって異なりますが、自然言語処理はラジオです。教授がテキストを読み上げ、受講者想定の方が聞き役に周り、適宜質問や相槌を打って講義を進めていくという流れでした。
音だけ追うというのは苦手な人には抵抗があるかもしれません。 図を用いて解説する部分は流石に音だけでは追うのにさすがに厳しいものがありました。 一部でも映像授業があれば良いと思います。
事前知識はあまり必要ないと思います。数学面からはあまり触れられず、条件付き確率が分かれば問題ない感じです。機械学習の知識もこの講義を受けようと思った方ならとくに問題ないと思います。
最後の講義になると、しゃべってコンシェルの開発話や、京大学長のお話を聞けたりと、ボーナストラック的な部分があります。 テキストにはない部分で独学ではなかなか聞く機会はないのでここが差分になると思います。
テストについて
テストは中間テストみたいなものがあり、これをパスしたら期末テストを受けられます
コロナ下なのですべて在宅でした。内容はテキストかの出題で4択問題。むしろ読解力の試験のような感じです
まとめ
ざっと自然言語処理技術の概略を掴むには良いと思います。構文解析などは機械学習の技術書ではあまり扱わないので導入してはありがたいです。
ただ、講義はほぼテキスト通りに進むためテキストを読んで十分理解できる方や、前述したエピソードトークなどに興味がない方は、わざわざ単科でお金を払って(まあまあかかる)講義を受けるメリットは薄いと思います。
放送大学は社会人の学び直し機関としてとてもありがたいです。 データ構造とかもあるので、引き続き興味にある単科講義をとってみようかと思っています。
おわり。
メラノーマコンペの思い出
2020/6/28 ~ 2020/8/18でKaggleで開催されたSIIM-ISIC Melanoma Classificationに参加して、銀メダルだったのでその思い出です
コンペの概要等はチームメンバーのkaerururuさんのブログに載っているのでそちらもご参考下さい kaeru-nantoka.hatenablog.com
私のソリューション概要は3.に載っています
1. 参加動機
Twitter Sentiment Extractionで銀メダル圏からシェイクダウンをくらい、メダルなしに泣きながらLateSubをしている際に、チームメイトだったmobassir氏に「ちょっとやらない?」と声をかけられたのがきっかけでした。
画像タスクが去年の今頃のAPTOS以来だったので、リハビリとTensorFlowの学習にいいかなあくらいの軽いモチベーションで参加しました。
2. 時系列
初期
本格的に参加したのはコンペが始まって1ヶ月ほどたったタイミングでした。この頃からEfficientNetを使って モデルサイズ x 画像サイズ でアンサンブルするとスコアが伸びることがDiscussionに報告されていました。画像なんも分からん状態なので、とりあえずPublic Notebookを写経しながら自分のパイプラインを改修してました。
中期
シングルモデルでCVを改善しても、PublicLBは改善しないという状態に陥りました。他の参加者も大体似たような感じだったと思います。
mobassir氏が知人を誘い3人になったので、一回アンサンブルを試してみましたが、結果は同様で、CVは改善するが、PublicLBはほとんど改善しなかったので絶望した覚えがあります。 チームで参加していなければ多分投げていました。
後期
mobassir氏が、Twitterでよくお見かけしていたkaerururuさんと、氏とよくチームを組んでおられるToru Itoさんをチームに勧誘しました。開催中コンペで日本人とチームマージするのは初めてだったので、モチベーションがだいぶ回復しました。軽く情報共有した後、各人でモデルを改善して、私がモデルを回収してアンサンブルに含める感じで進めました。
中期から私がアンサンブルのスクリプトを書いていたため(と言ってもアベレージをとるナイーブなものでしたが)、流れで最後までアンサンブルは私が担当してました。
上手くいかなかったらチームの努力が水の泡になるので、まあまあプレッシャーがありました。アンサンブル担当は当分したくありません。
最終的なCVは0.951ほどで、Publicでは1000thくらいだったと思います。前々からHigh Publicスコア(銅圏くらい)とHigh CVスコアの結果を提出しようと多数決していたため、最終サブの一つにしました。
結果的にこれがPrivateで最も高いものとなり、Trust CVでシェイクアップし無事に銀メダルでフィニッシュでした。
High Publicスコアのサブはことごとくメダル圏外でしたが、メンタルヘルスの維持に役に立ちました
3. ソリューションの概要
基本訓練したモデルは捨てずに、アンサンブルに加えてCVを伸ばす方針でいきました。
CVはChris氏が公開していたtriple stratified leak-free CV1で、基本的に2018年の画像をExternalとして含めて訓練しました。
モデルはEfficientNetを使用。Headなど特に工夫はなく、augumentaionもPublicで共有されていたものを使用しました。
- ベースラインとなるimagenetからの重みを使ったもの
- B5 512
- B4 512
- B4 384
- noisy-studentからの重みを使ったもの
- B5 384
- B5 480 + augmentationにcoarse dropout
- pretraining model
- その他
- SEResNeXt-50
- 画像サイズ 192 upsampleデータ使用
- ほかにもXceptionやInceptionResnetなどを試しましたが、最終的にこれだけ残りました
- metaデータ
- 画像と紐づく年齢等のデータ
- LightGBM
- PublicのNotebookを参考にしつつ、RGBのヒストグラムとかを特徴量に追加した
- SEResNeXt-50
画像はほとんど分からない+ドメイン知識なしなので、いろいろ試してモデルを積木した感じです。
面白味やインパクトに欠けると思いますが、粛々といろいろ試してローカルCVを改善するという点で、成功体験が得られたので個人的には良かったです。
アンサンブル
変換方法がいろいろシェアされていましたが、私の体感では大体
power << rank ~ simple < log でした。rankでスコアが伸びなかったのが謎でした。
weightを調整したかったので、LogisticRegressionやXGBoost等を試しましたが、4GM本2に書いているOptimized AUCが一番CVが上がりました(simple avg: 0.95096 → 0.95147)。
weightでcvがまあまあブレるので工夫として、train_test_splitして、trainとvalのスコアの偏差が小さいものでweightの平均をとりました。結果に寄与したかは不明です。
どのモデルをアンサンブルするかは人力グリッドサーチしてました。この辺なにがベストなのか知りたいです。
4. 終わりに
実はチームメンバー各人のモデルでは、終了間近に作成されたToru Itoさんのモデルが最もCV,LB共に高かったのですが、アンサンブルに含めるとなぜかCVが落ちるという結果になったので、時間的余裕もなく含めることができませんでした。
Private Share粛清後の最終的な順位が39thで、上位と比べてもクリティカルな差があまりなかったようなので、上手く組み込めたら金もあったかなあと思うと悔しいところです。
最終的にTwitter Sentiment Extractionの二の舞にならなくて良かったです。
金とって早くMasterになりたいです。
おわり
Coursera Applied Social Network Analysis in Python 体験記
Courseraでネットワーク分析の講座を探していたらちょうどPythonを使った講座を見つけたのでその体験記
モチベーション
ピープルアナリティクス分野でネットワーク分析の話題をちょいちょい耳にするのでPythonで基礎的な分析ができることを目標に講座を受講
受講前のレベル
- (専門書ではない)ネットワーク分析に関する本を数冊
- Courseraの講座の修了経験2つ
この講座で身につくこと
感想
講座自体はサクサク進みました。各週の最後には実際にライブラリを使ったクイズ形式の演習課題があります。この講座の前にCourseraでKaggleに関する講座*1を受けていたので、それに比べるとはるかに簡単でした。pandasが使えれば十分です。
講座の進み方は各セクションでネットワーク分析に使う指標の定義説明、その後簡単な数値計算の例を通して解説となっています。スライドで計算例がかなり丁寧に説明されているので英語が苦手でも問題ないと思います。難しい数式もありません。
予備知識は必要ないと思いますが、スケールフリーやスモールワールドといった複雑ネットワークの基本用語を知っていると最終週のセクションが楽になると思います。
この講座を通して断片的な知識が得られるとは思いますが、プロジェクトベースドラーニングのような具体的な分析例はないので、実際の分析に役立てる場合はさらなる勉強が必要です。
とりあえずnetworkXライブラリの使い方と各ネットワークの指標をさらっと理解したい人にはおすすめします
講座で使用しているnetwotkXのライブラリはバージョンが古いので、最新バージョンだと違う動作になってました
Kappa係数のメモ
Kappa係数
Kaggle Courseraの評価指標のセクションでKappa係数が出てきました。
検索しても中々情報が出てきませんが、最近だとQuadratic Weighted KappaがPetFinder.my Adoption Prediction | Kaggle で評価指標になっています。
一見すると統計検定2級くらいの知識っぽいですが、勉強した記憶がなかったのでメモ的にまとめてみました
*あくまでもメモです
定義
:一致率
:偶然の一致率
カッパ係数 kappa coefficient ある現象を2人の観察者が観察した場合の結果がどの程度一致しているかを表す統計量。カッパ統計量や一致率とも言う。0から1までの値をとり、値が大きいほど一致度が高いといえる。カッパ係数 | 統計用語集 | 統計WEB
計算手順
ある二人の医師(A, B)が患者の病気の診断を行うとする。患者40人をそれぞれが診断した結果は以下になった
| A\B | NO | YES | |
| NO | 20 | 4 | 24 |
| YES | 4 | 12 | 16 |
| 24 | 16 |
医師Aと医師BのNOでの一致患者が20人でYESでの一致患者が12人という想定です
単純な一致率はYESとNOが一致した割合で対角成分から以下のように求めることができます
次にAとBの診断がたまたま一致するような期待度を求める。
例えばYESで考えるとAは16/40でYESと診断し、Bも16/40でYESと診断するので
くらいの人数が一致するであろうと考えられる。同様にして他も計算すると
| A\B | NO | YES | |
| NO | 14.4 | 9.6 | 24 |
| YES | 9.6 | 6.4 | 16 |
| 24 | 16 |
よって偶然の一致率は
Kappa係数の定義より
となる。
つまりKappa係数とは偶然一致することが期待される分を除いた残りがどれくらいの割合で一致したかを計算した値であるといえそうです
Pythonで計算
cohen_kappa_scoreメソッドを使えば計算できます。
confusion_matrixで集計表と同じ結果がでることも確認しておきます。
import numpy as np from sklearn.metrics import confusion_matrix, cohen_kappa_score A = np.array([0, 1, 0, 1, 0, 0, 0, 0, 1, 1, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0, 1, 1, 1, 0, 0, 1, 0, 1, 1, 0, 0, 0, 0, 0, 0, 1]) B = np.array([0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 1]) confusion_matrix(A, B) '''output array([[20, 4], [ 4, 12]]) ''' cohen_kappa_score(A, B) '''output 0.5833333333333333 '''
重み付きkappa係数
例として患者の状態を良いを0として0(良),1(普通),2(悪)のように多段階評価している場合を考えます
- Aが患者に0(良)の評価を与えて、Bが患者に1(普通)の評価を与えたとき
- Aが患者に0(良)の評価を与えて、Bが患者に2(悪)の評価を与えたとき
を全く同じ一致として考えることは正しいと思えません。
つまり遠い一致になったときはペナルティーを与えて調整する必要があります。
例として以下の集計表を考えます
| A\B | 0 | 1 | 3 | |
| 0 | 5 | 5 | 1 | 11 |
| 1 | 4 | 10 | 3 | 17 |
| 3 | 5 | 1 | 6 | 12 |
| 14 | 16 | 10 | 40 |
偶然の一致も2x2と同様に計算します
| A\B | 0 | 1 | 3 | |
| 0 | 3.85 | 4.4 | 2.75 | 11 |
| 1 | 5.95 | 6.8 | 4.25 | 17 |
| 3 | 4.2 | 4.8 | 3 | 12 |
| 14 | 16 | 10 | 40 |
重みの考慮はいろいろあるようですが、scikit-learnの実装では以下のように計算されています。
i, jはセルの位置
2乗で重みをとったのでQuadratic Weighted Kappaと呼ばれるそうです。そして一般的に重み付きといったらQuadratic Weighted Kappaを指すようです。
| A\B | 0 | 1 | 3 |
| 0 | 0 | 1 | 4 |
| 1 | 1 | 0 | 1 |
| 3 | 4 | 1 | 0 |
この重みとそれぞれのマトリックスの要素の積をとり、以下のように計算します
xは実際の一致で、mが偶然の一致
Pythonでの計算
cohen_kappa_scoreでweights='quadratic'と指定すれば簡単に計算できます。
A = array([1, 1, 1, 1, 0, 0, 2, 1, 1, 2, 1, 1, 1, 1, 1, 2, 2, 0, 0, 2, 0, 0, 2, 2, 2, 1, 0, 2, 0, 1, 2, 1, 0, 1, 2, 2, 1, 0, 1, 0]) B = array([1, 1, 1, 1, 0, 0, 2, 0, 1, 2, 0, 1, 1, 2, 2, 2, 2, 1, 1, 0, 0, 1, 2, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0, 2, 0, 2, 1, 2, 1, 1]) confusion_matrix(A, B) '''output array([[ 5, 5, 1], [ 4, 10, 3], [ 5, 1, 6]]) ''' cohen_kappa_score(A, B, weights='quadratic') '''output 0.21610169491525433 '''
2x2の場合は対角線上の要素でKappa係数を計算しているので直感的で分かりやすいです。
重み付きKappa係数の場合は対角成分を0にして一致していない要素で不一致率を出して、1から引くことで一致率としているイメージでしょうか?
いろいろ調べましたが、よく分かりませんでした。 詳しい方がいたらコメント等で指摘いただけると勉強になります。おわり。
Coursera "How to Win a Data Science Competition" コース体験記
Courseraで開講中のHow to Win a Data Science Competitionを受講して無事に完走しました。
文字通りデータサイエンスコンペで勝つ方法をロシアのTop Kagglerが直々に講義してくれます。
よかった点
EDAセクション
Target Encodingセクション
- どうしてTarget Encodingが効くのか、どうしてリークに繋がるのかを簡単に説明してくれる
- リークしやすいのでregularizationの手法をいくつか紹介して実装演習まである
Stackingセクション
- StackNetライブラリ作者直々の講義で、ナイーブな事例+動くスライドを用いて説明される。すごいわかりやすかった
- 一方でValidation手法がありすぎて結局どれがどんな時にいいんだ...と整理できない面も
講師陣が参加した過去コンペの取り組みの紹介
悪かった点
ほとんどが私の知識が及ばないことに起因していると思うのであまりありません。強いて言うならば
Leakageセクション
- 過去に開催されたコンペのLeak事例の紹介。全然わからんで有名なセクション
だれか日本語で教えてください...
たまに課題に対してなにをすればいいか説明不足で不親切だなあと思うところも
感想
かかった時間
- 仕事終わりに大体1日2時間くらいやっていました。最終課題は結構時間をかけてやったので全て含めると60-70時間なったのかなと思います。ちなみにコースでは”6-10 hours/week"と書かれています
必要なレベル感
- 多少英語がわからなくても説明内容に察しがつくので、1, 2度コンペに参加したことがある位がちょうど良いと思います *1
- 数学に関して言えば、ところどころ(特に評価指標)はあった方が理解が深まると思いますが、全体的にはほとんど求められません
日本語でも説明を理解できるか怪しいのに英語のビハインドが加わりなおさらわからん。という自体に陥る箇所が多々ありました
英語ネイティブは本当に羨ましいなあと思った次第です。 英語は得意だけど機械学習コンペは入門者みたいな人には圧倒的にオススメします*2
それでもコンペに特化した教材はあまり存在しないので普通に楽しかったです
進め方
最初はただビデオを見ているだけでしたが、紹介される手法や知識の雨あられに整理が追いつかず、後からメモをとって進めるスタイルに変更しました
最終課題以外はコースの表記通り3h+αくらいで終わると思います。
最終課題はコース用に実際にKaggleでホストされているコンペに参加して一定スコアを取ることです。合格点は明示されていませんが、ベンチマークが1.16で大体1.0を切れば合格できるという噂。コース内容に沿った解法ができているかのソリューションのペアレビューもあり、まとめるのに結構骨が折れました
Courseraの指示ではWeekを進めるごとにStep By Stepで最終課題のコンペに取り組みましょうとなってます。しかし、一旦コンペに取り組むとそっちに気が向いて上手くリソース配分できないと思い、一先ずコースのビデオと課題をガシガシ進めました
最終的に最終課題を取り組むに当たって試したいテクニックなどをビデオで復習するような感じに落ち着き、よい復習サイクルになったと思います
おそらく最終課題のコンペ自体は誰でも参加できるので、受講時間を稼ぐためにもとりあえず参加して、流れがある程度固まった時点で受講を開始するのもアリかもしれません
おわりに
知識の整理になったし、なりよりTarget EncodingとStackingは習得したいテクニックだったので参考になりました
もちろん講座だけでコンペで良い成績を出すことはできないと思います。しかし、これから学ぶためのキッカケにもなったので、私のような入門者にはとても参考になる講座だと思います